DB 기본 이론
DB의 정의
DB란 ? Database 즉 데이터의 집합
DBMS란? DataBase Management System.
즉, Database 를 관리하기 위한 도구들을 모아둔 시스템 (MySQL / Oracle / Mongo DB / ProtgreSQL 등등..)

DB를 사용하는 이유
DB를 사용하지 않고 데이터를 저장하는방법 : Textfile을 사용함.
웹 서버에 text파일을 만들어서 저장함.
→ 버그없이, 보안을 관리해야 되기때문에 고객 데이터가 망가지거나, 빠르게 필요한 text를 찾아가는 알고리즘이 필요해서 구현하기도 힘들고 관리가 매우 힘들다.
→ DB를 사용하면 이러한 문제가 해결된다.
DB의 종류
RDBMS (관계형 DBMS) : 구조 및 제약조건 (스키마)를 만든 후 값을 채워야함.
1
→ MySQL , Oracle 등등..
DBMS (비관계형 DBMS) : RDBMS와 다르게 구조로 저장하지 않는 DBMS를 의미.
1
→ Mongo DB, Redis
DBMS의 순위
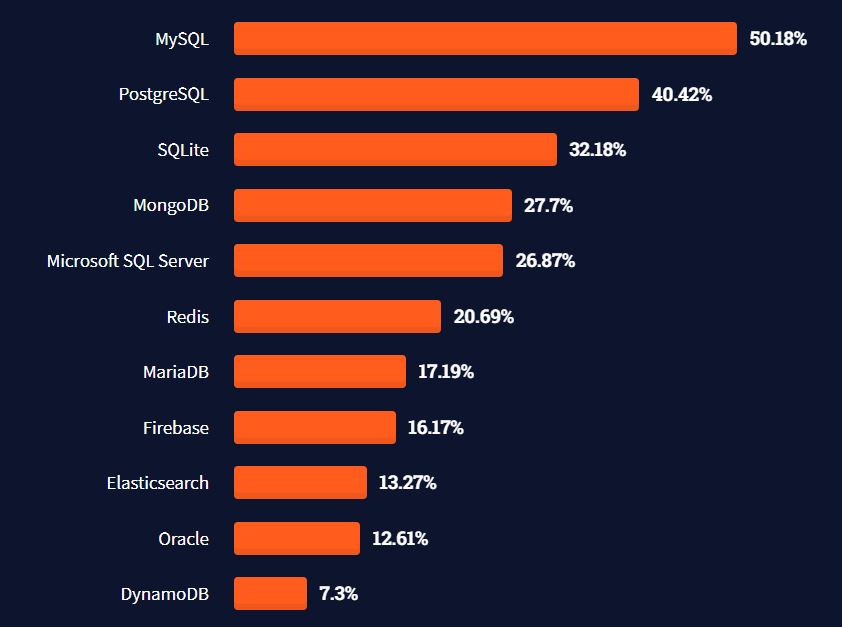
MySQL이 가장 많이 쓰이는 것을 알 수 있다.
DB의 구조
MySQL 기준
- 인스턴스 = DB서버 = 폴더와 같은 역할
- 스키마 = Database = 엑셀파일
- 테이블 = 엑셀파일 내부의 여러 테이블 표
(Oracle 기준에서는 4계층 구조를 사용함. Database와 Schema가 독립됨)
인스턴스(instance)
하나의 DB를 운영하기 위해 내부 Buffer/ 내부 저장공간 / 관리 도구들이 동작되는 부분.
운영이 필요한 모든 도구들을 모아 “서버 인스턴스”라고 부름
스키마(schema)
MySQL에서는 Database와 동일한 뜻.
스키마를 생성하는 명령어
- CREATE DATABASE {DB 명}
- CREATE SCHEMA {스키마명}
(둘 다 동일하다.)
DB의 관리
root 계정
모든 권한이 있는 root 아이디를 쓰다가 해킹이 되면, 큰 피해를 입는다.
그래서 사용자계정 권한이 없는 일을 할때만 사용한다.
(ex . 사용자 계정 추가 / 스키마 생성등.)
사용자 계정을 보통 사용함.
사용자 계정
허용된 스키마만 사용할 권한이 부여된다. 허용된 스키마에 Table 추가 후 SQL 명령어를 사용 또는 Workbench(GUI)를 이용하여 데이터를 추가, 로드, 수정, 삭제를 진행한다.
(CRUD : Create, Read, Update, Delete)
→ 사용자 계정에서 스키마 제거 및 편집은 불가능하다.
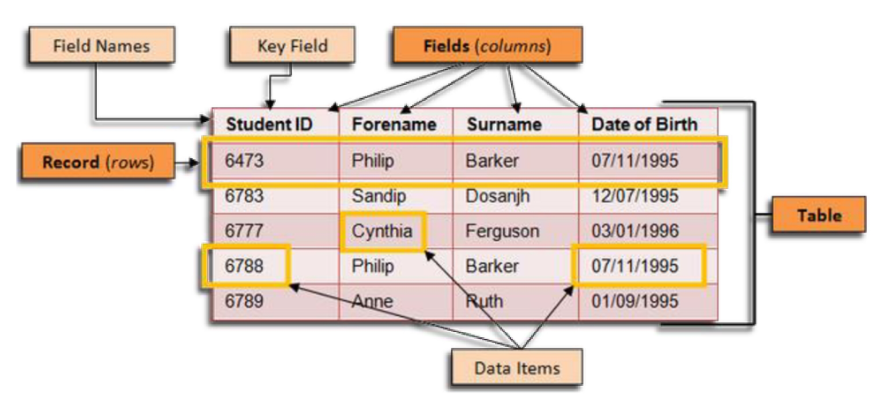
DBMS용어
- Field : 열을 의미하며 테이블에서의 속성을 의미한다.
- Record : 행을 의미하며 1개 데이터의 묶음을 의미한다.
- Items : 데이터 하나 하나를 의미한다.
DB 환경 구축
이제 DB를 쓰기위한 환경을 구축해보자.
MySQL 설치
-
MySQL 웹사이트에 접속하여 Download
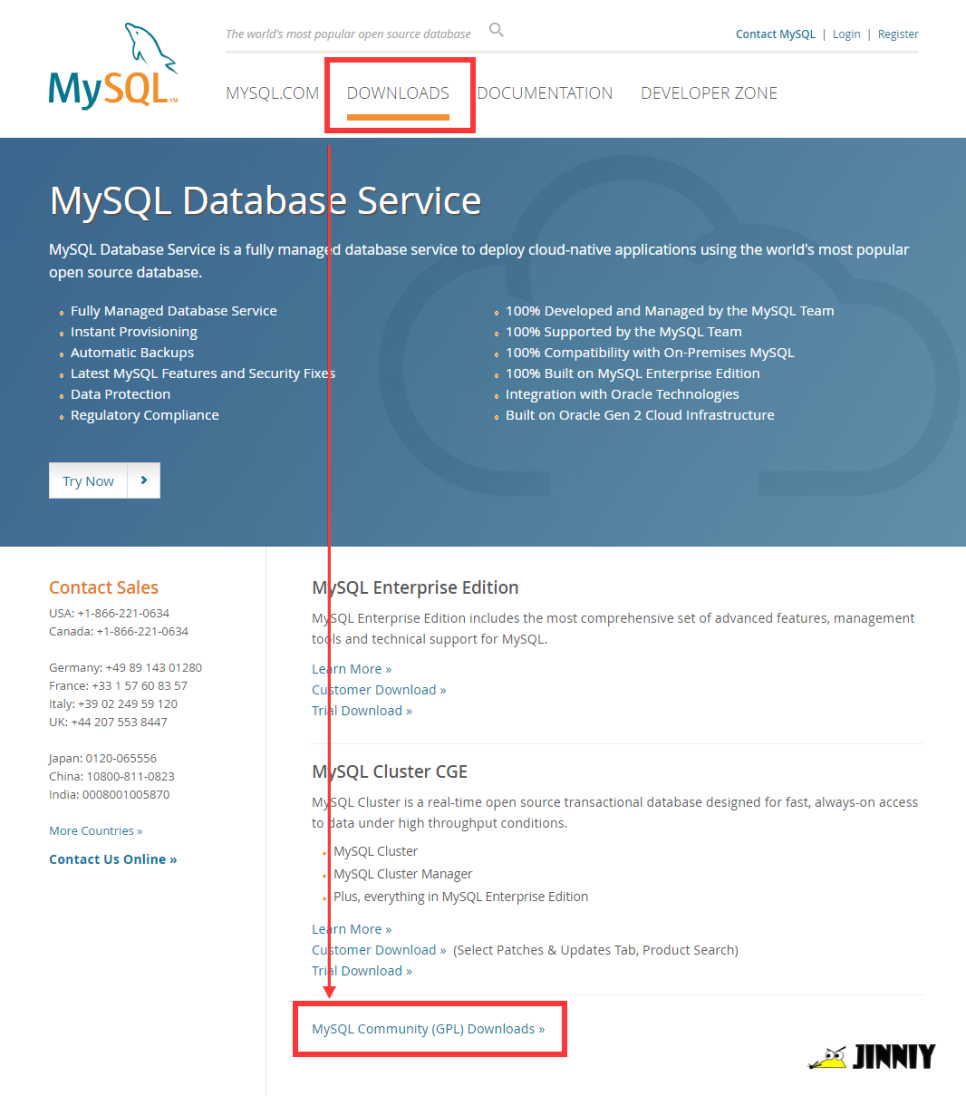
- MySQL Community (GPL) Downloads를 클릭
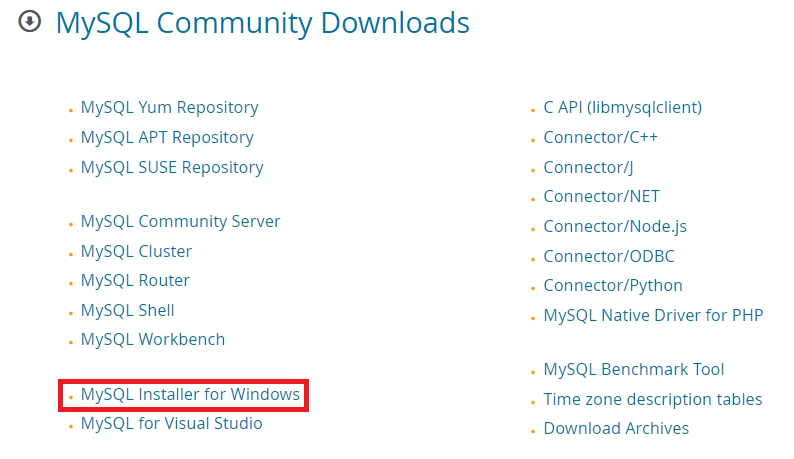
- 윈도우 기반이므로 MySQL Installer for Windows를 클릭
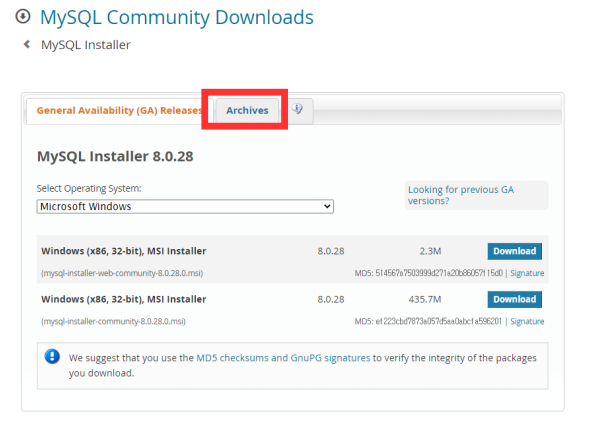
- 이슈 문제 때문에 다른버전을 선택한다.
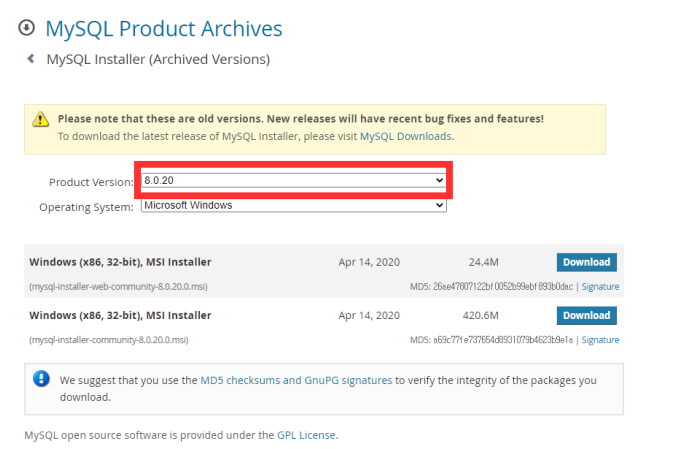
- 위의 파일을 다운받는다.(로그인은 무시해도 가능하다)
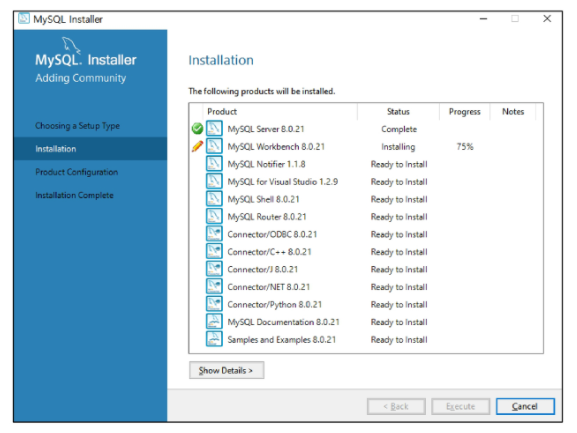
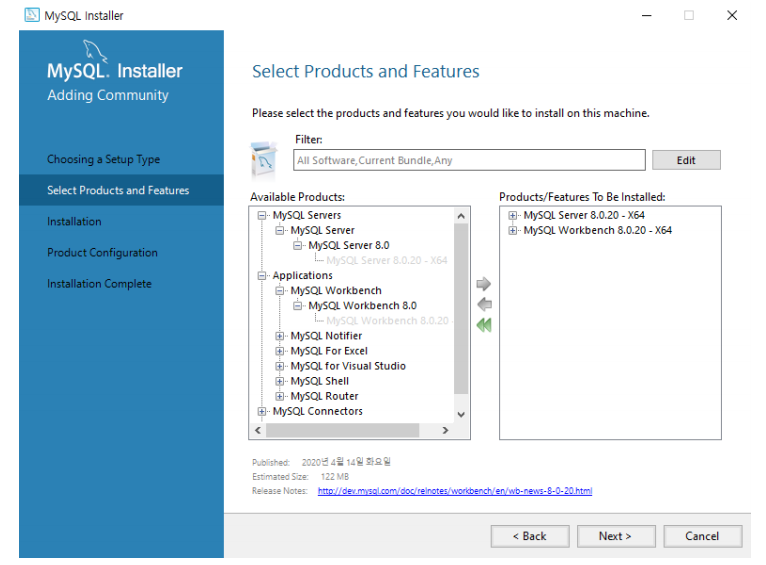
- MySQL server(필수!!), MySQL Workbench(GUI) 만 설치해도 됨. (필요에 따라 추가설치)
- 공부를 위해서 Samples and Examples들을 추가로 설치하였음.
(원하는 Type 에 맞게 설치를 진행하고 원하는 도구들을 추가하여 설치한다.)
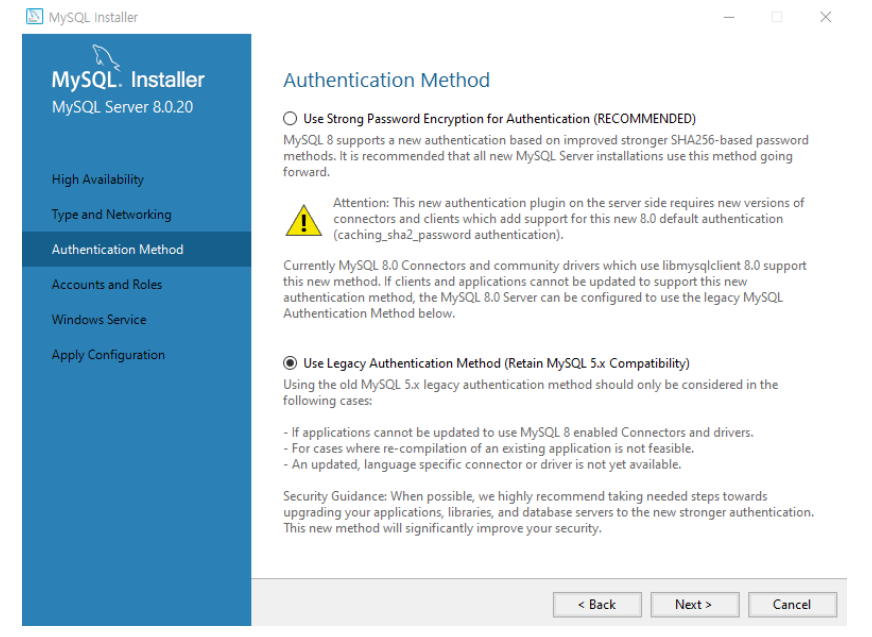
- 레거시를 선택한다.
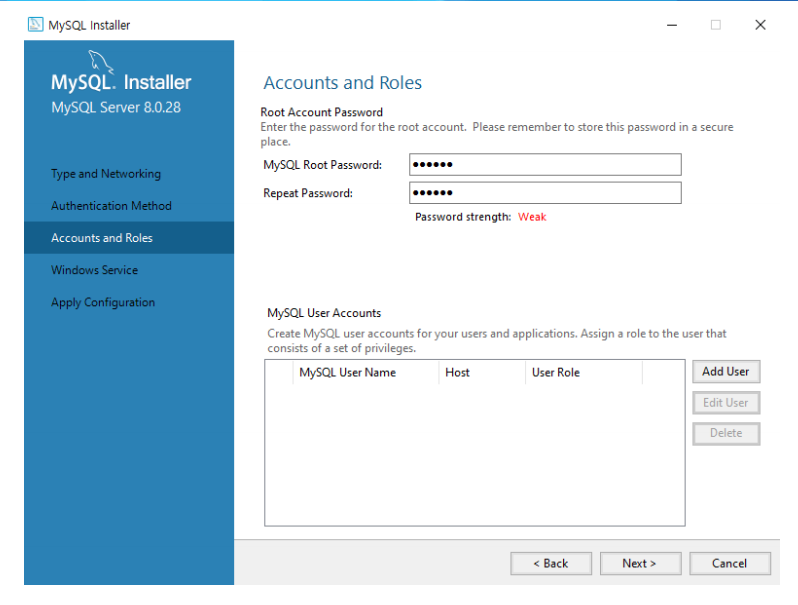
- root 계정에 비밀번호를 설정하고 설치를 마무리 한다.
- 비밀번호를 잊으면 다시설치하거나 비밀번호찾기를 해야함.. 잊지않도록..!!
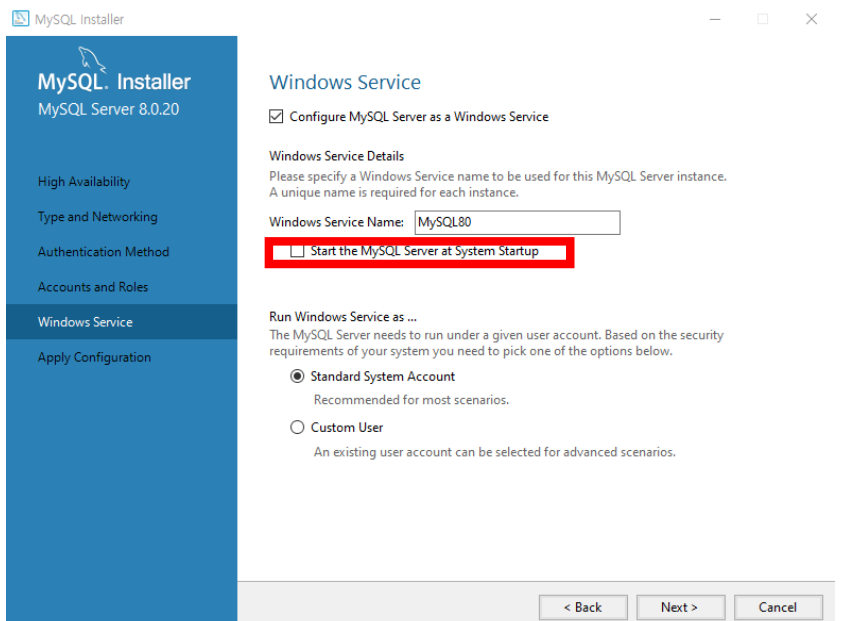
- 다음 옵션을 해제 하자. (사용할때만 수동으로 시작하기 위해서.. 아니면 부팅 시 자동으로 실행됨.)
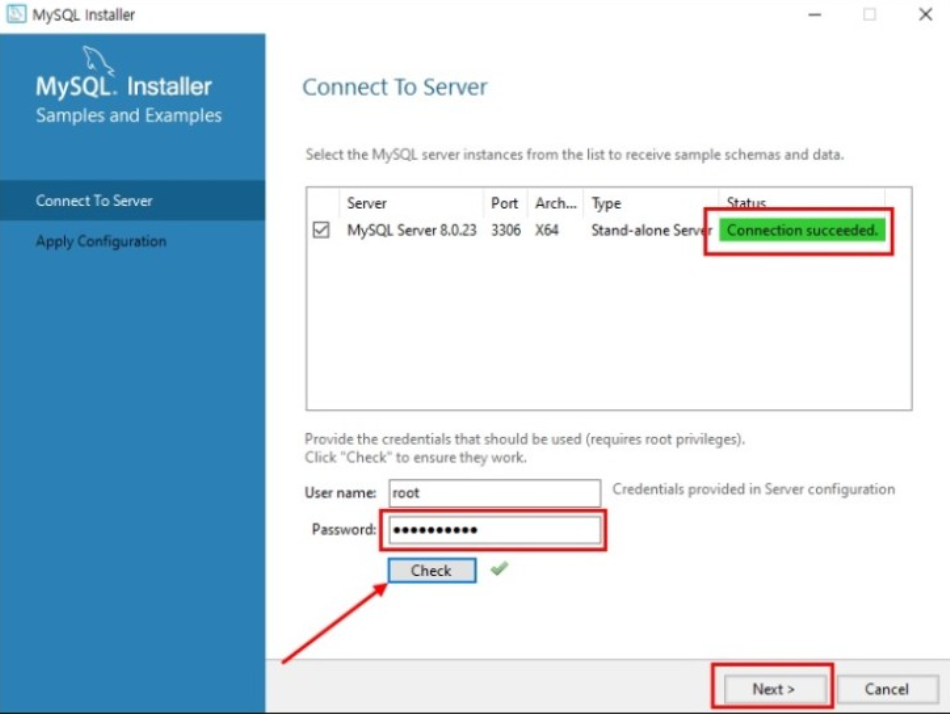
- 이 화면이 나올때 까지 Next를 하고, 앞에서 설정했던 root 비밀번호를 입력하고 check버튼을 눌러 Connection succeeded가 뜨는 지 확인하고 설치를 종료한다.
MySQL Workbench(GUI)
설치된 Workbench에 접속하게 되면 다음과 같이 접속할수 있다.
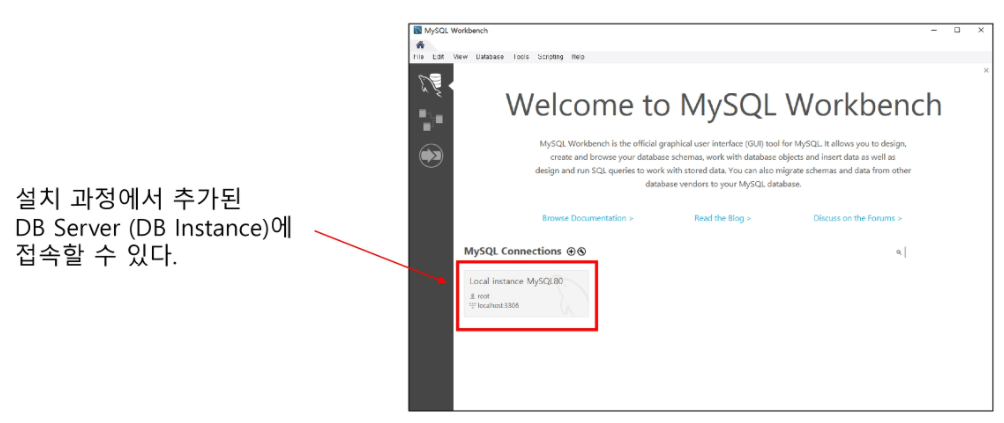
해당 서버에 접속 시도시,
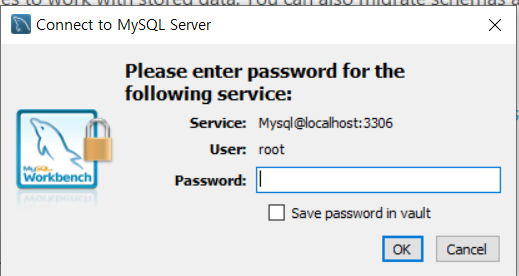
다음과 같은 창이 뜨는데, 설치과정에서 입력한 Password 를 입력하면 root계정에 접근가능하다.
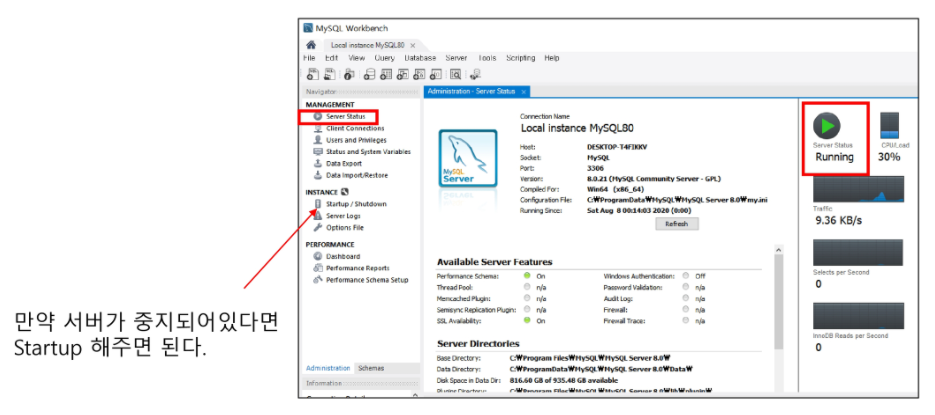
왼쪽 탭의 Administration > Serever Status를 확인하면 서버가 현재 정상적으로 작동중인지 확인 가능하다.
DB테이블을 생성하기 위해서 다음 아래 과정을 진행하였다. (사용자계정을 이용하였다.)
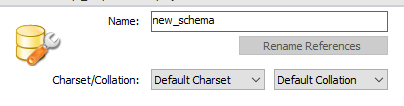
- 스키마 생성하기
이번에는 왼쪽 Navigator 에서Schemas를 선택후,
상단의 스키마 생성 버튼으로 Schema 추가.

스키마 명을 등록한다.
- 새로운 계정 생성하기
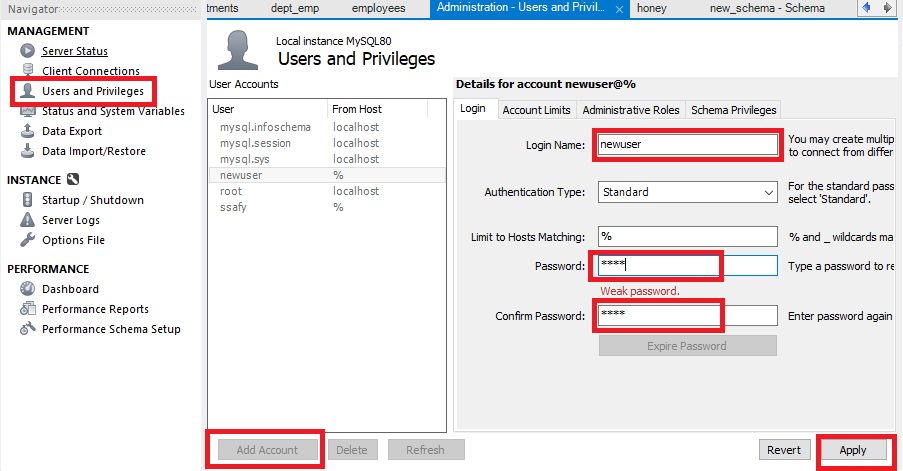
다시 Navigator 에서 Administration 에서 Users and Privileges 탭을 선택하여 새로운 계정을 생성해준다.
Add Account » 사용자이름 및 패스워드입력 » Apply
- 생성된 사용자에 스키마 권한 부여하기
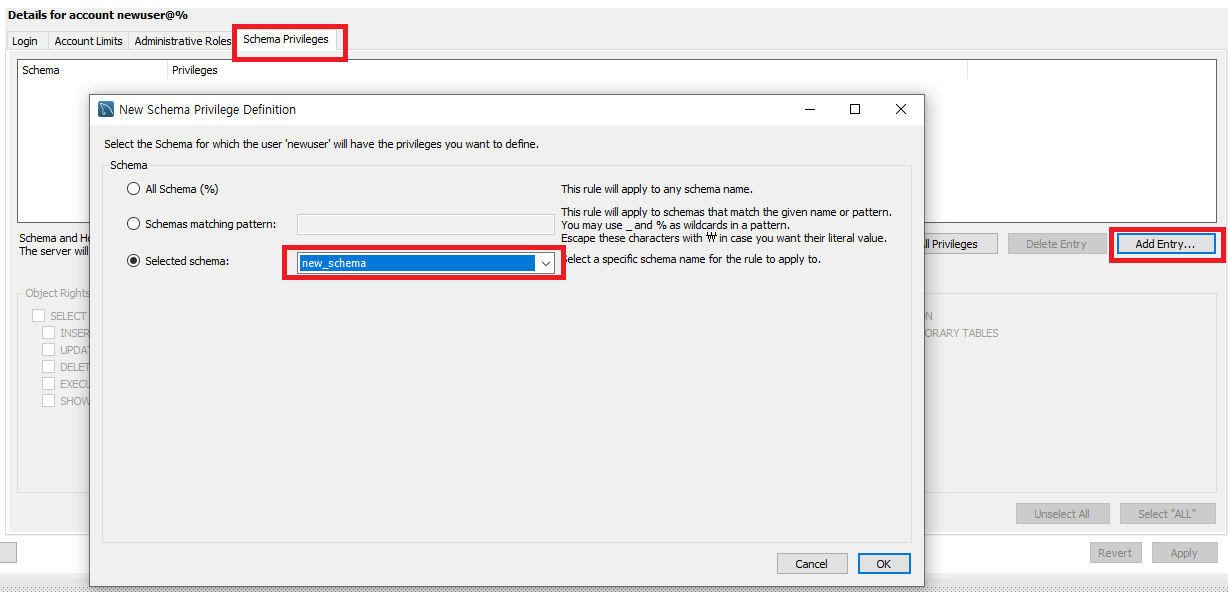
Login 탭이 아닌 Schema Privileges 탭으로 진입하고 Add Entry.. 를 클릭하여 사용자 계정에 넣고자 하는 schema들을 모두 선택해준다.
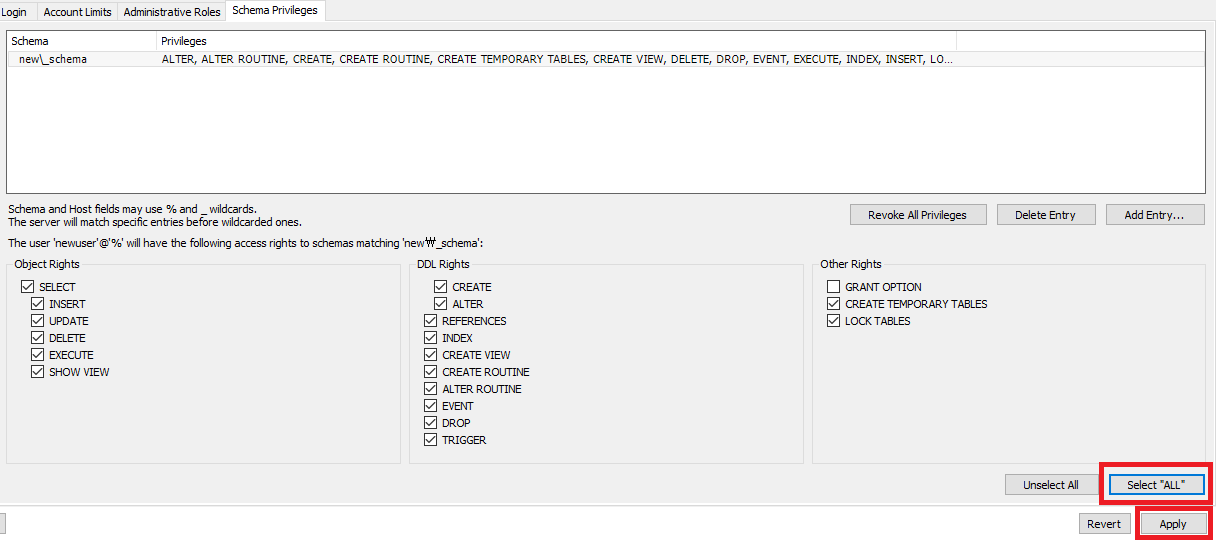
각 스키마 마다 사용자계정이 사용할 수 있는 권한을 각각 부여해주고 Apply를 한다.
여기서는 Select “ALL” 버튼을 통해서 사용자의 계정에서 해당 스키마의 모든권한을 사용할 수 있게 만들었다.
- 사용자 계정 접속
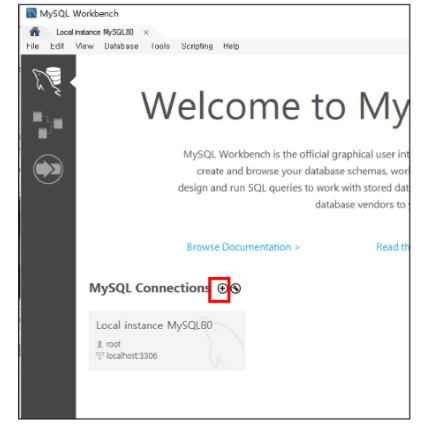
root 계정을 빠져나와 다음 +버튼을 눌러서 새로운 서버를 생성해보자.
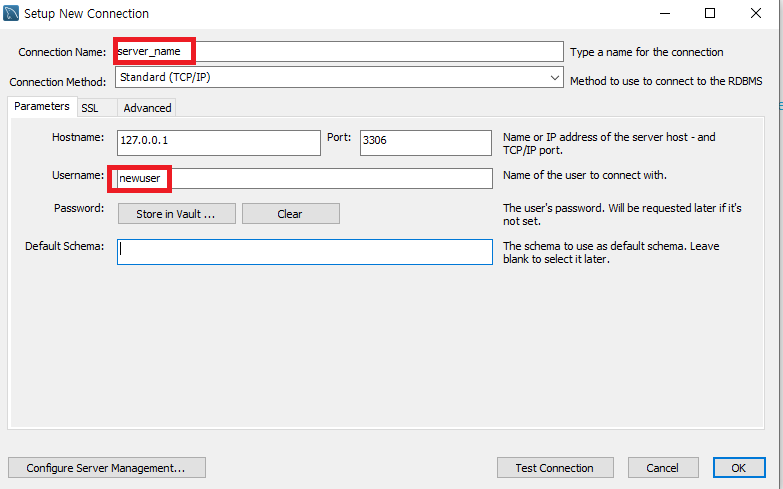
Connection Name은 Workbench의 초기 화면에 나올 이름
Username은 앞에서 생성한 사용자계정의 이름을 의미한다.
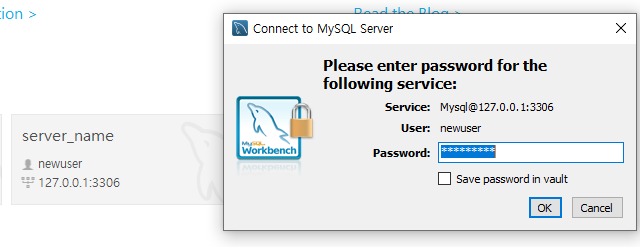
새로 생성된 사용자 계정으로 접속이 가능해졌다.
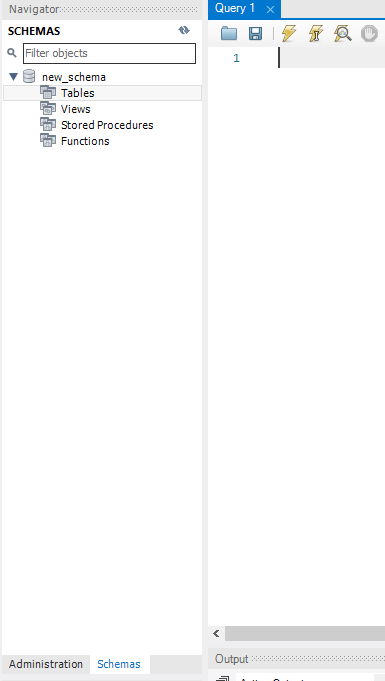
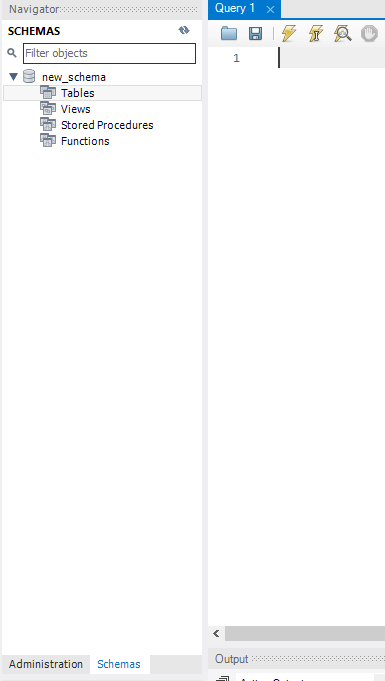
Navigator의 Schemas로 접속을 하면
다음과 같이 나오는 것을 확인 할 수 있다.
앞에서 권한을 부여한 스키마가 생성되어있다.
- 테이블 생성하기
스키마 내부의 태이블에 오른쪽 클릭을 하면 뜨는 Create Table을 클릭하면 다음과 같은 창이뜬다.
(또는 사용할 스키마를 더블클릭 후 상단의 테이블 생성아이콘을 클릭하면 된다)
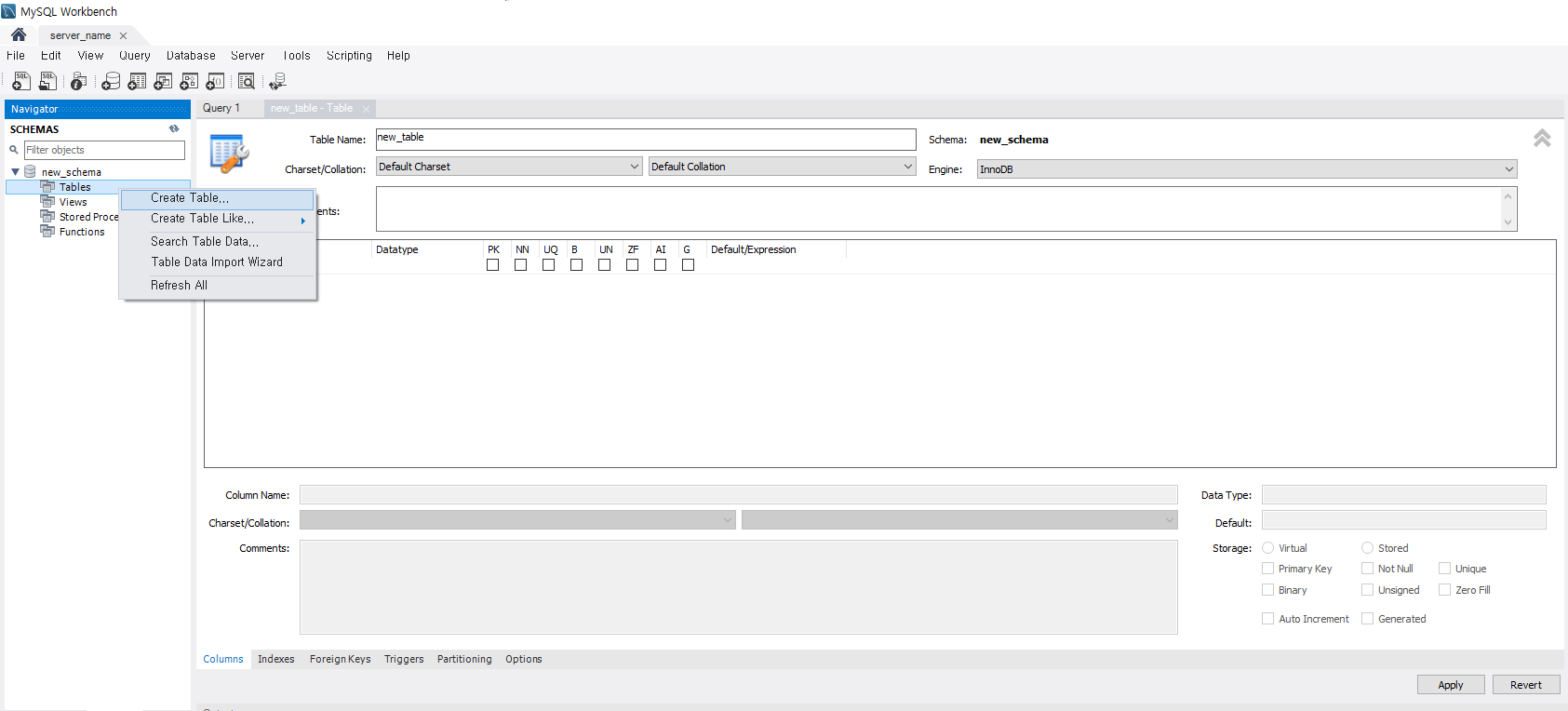
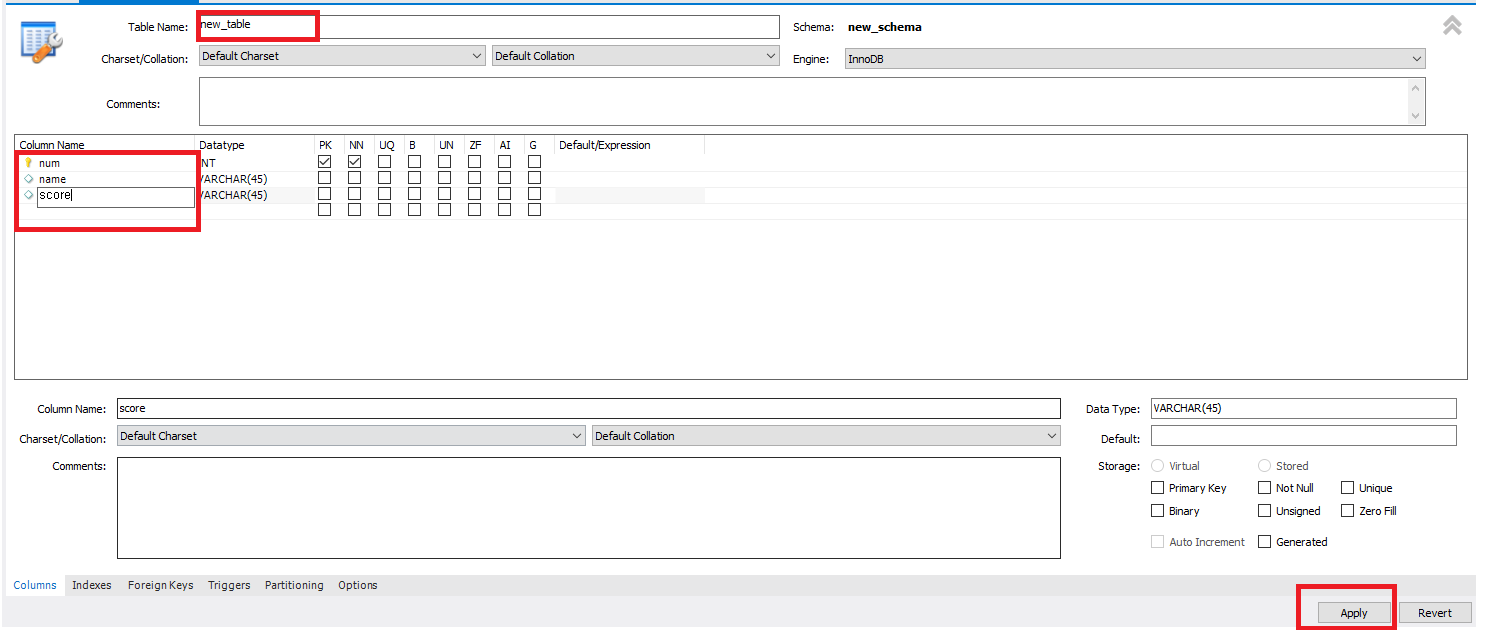
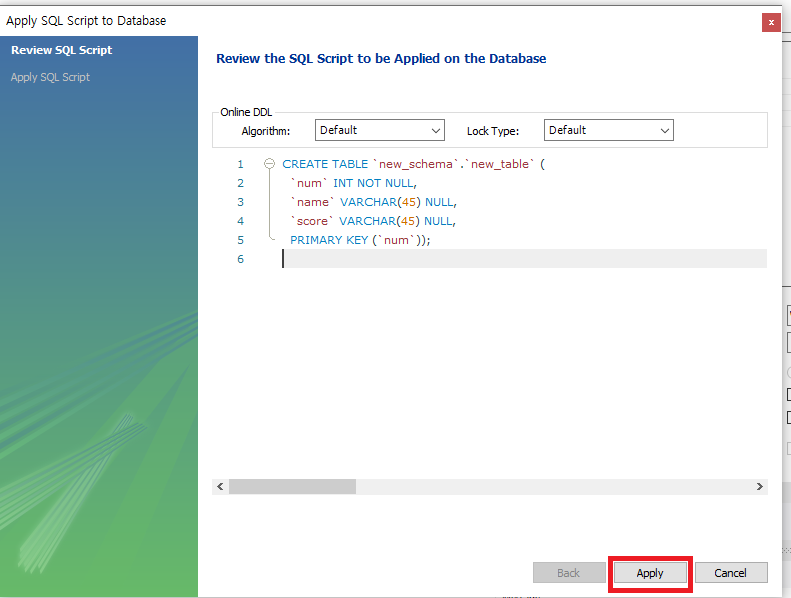
테이블명, 열에 들어갈 목록(Fields)를 입력하고 Apply를 하여 기본적인 테이블 형성을 완료하였다.
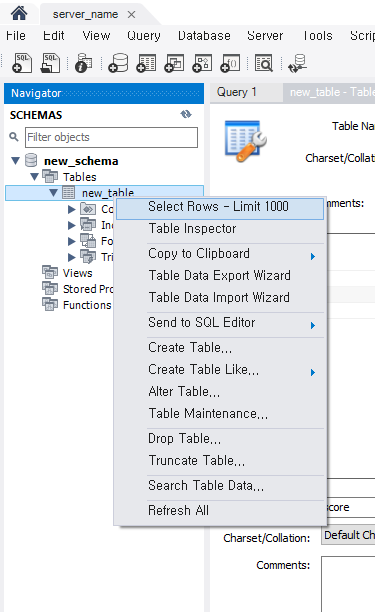
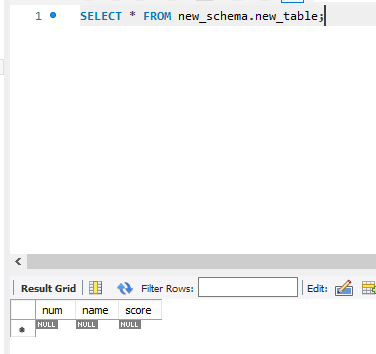
방금 생성된 테이블을 오른쪽 클릭하여 Select Rows - Limit 1000을 클릭하면 생성된 테이블을 직접 확인할 수 있고, 이제 SQL 명령어를 이용하여 테이블을 확인 할 수 있게 되었다.
- 테이블에 내용 채우기
테이블에 내용을 채우는 방법은 두가지가 있다.
1
2
3
4
5
6
7
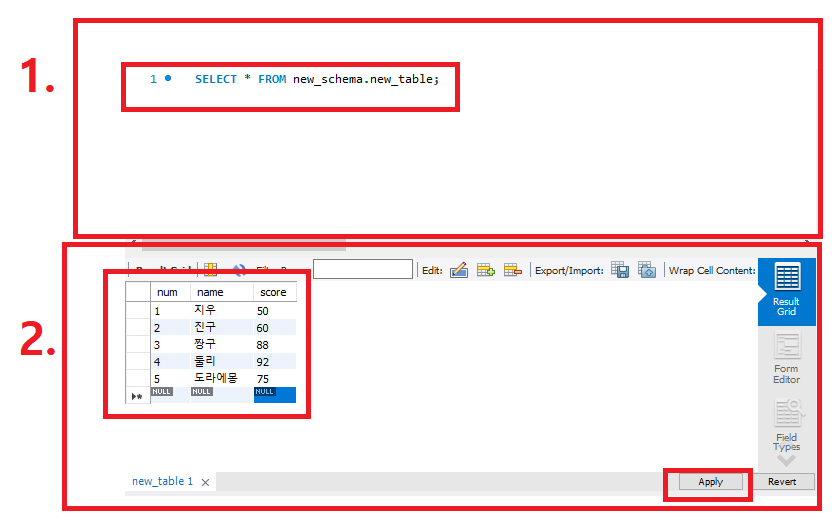
1. SQL 명령어를 이용해서 내용의 채우고, 내용을 확인한다.
(번개아이콘을 눌러 결과를 확인할 수 있다. <u>**excute 단축키 : Ctrl + Shift + Enter**</u>)
2. 직접 GUI를 이용해 사용자가 데이터를 입력하고 적용하는 방법이 있다.
(데이터 내용을 변경하고 Apply 버튼을 눌러 반드시 적용해주어야한다.)
※ 웹을 이용한 DB환경
웹에서 다양한 샘플데이터를 이용하여 DB를 사용해 볼 수 있다.
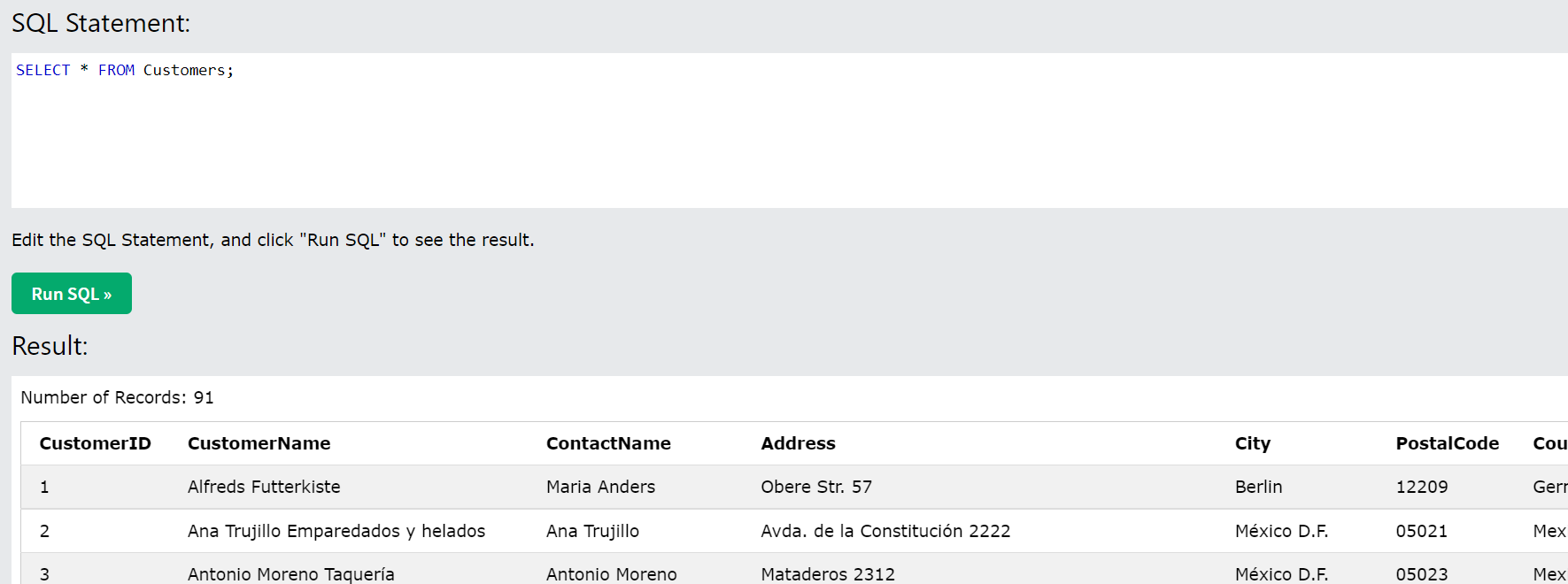
Data Backup
Data Export : 현재 Data를 외부파일로 추출
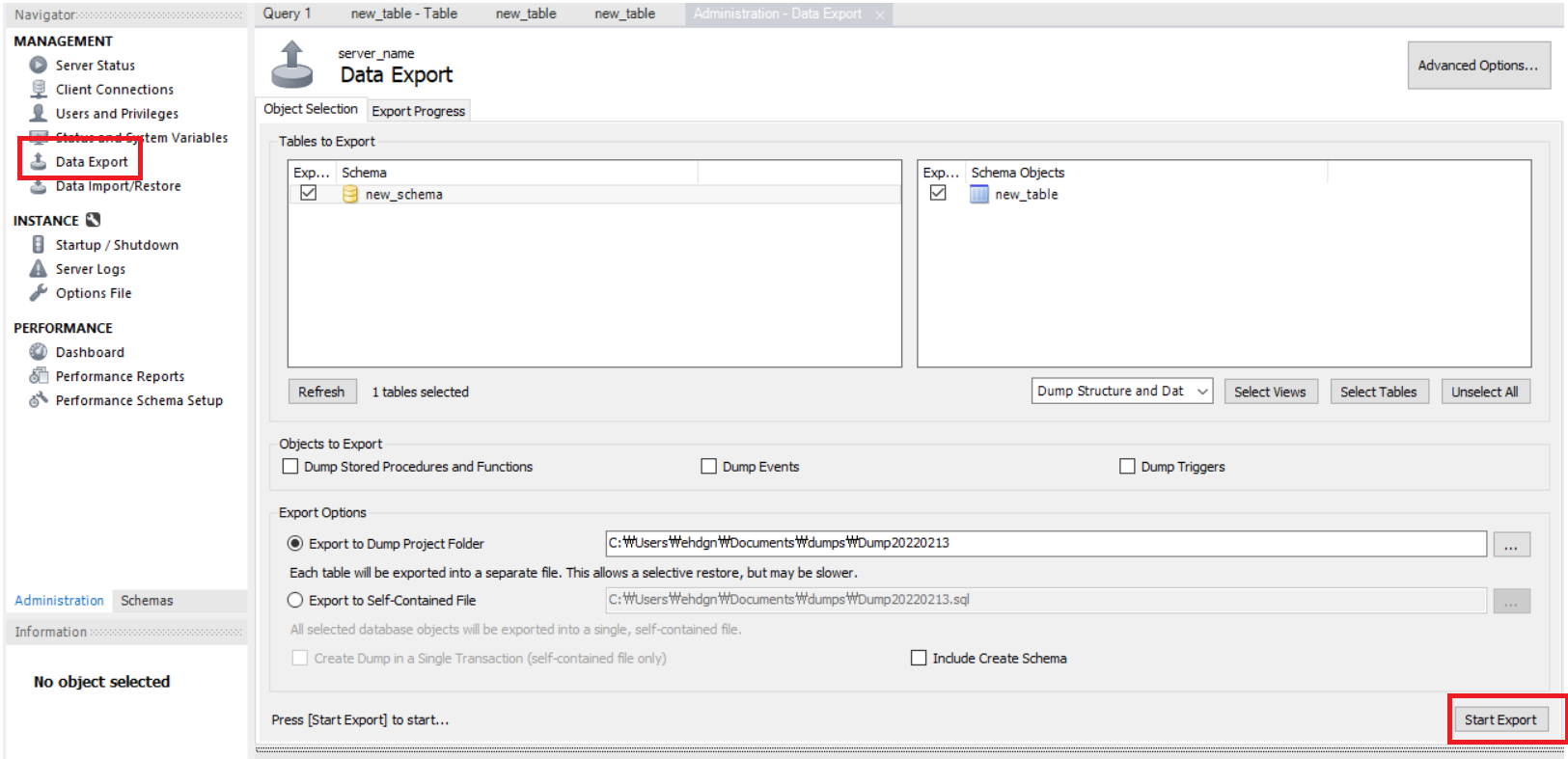
Data import : 제거된 데이터를 복구, 추가된 Table은 삭제하지 않는다.
외부로 추출한 폴더를 불러와서 import를 시켜준다.
SQL 명령어
SQL 에서는 대소문자를 구별 하지 않는다.
CRUD : Create + Read + Update + Delete
C : INSERT INTO ~ VALUES
R : SELECT
U : UPDATE ~ SET WHERE
D : DELETE FROM ~ WHERE
1
2
3
4
5
6
7
INSERT INTO 테이블 VALUES (값1, 값2, 값3 ...);
SELECT 필드 FROM 테이블;
UPDATE 테이블 SET 필드 = 값 WHERE 레코드 조건;
>>
UPDATE 테이블 SET 필드 = 값 -- 적용하면 모든 레코드들이 한번에 업데이트 될 수도 있음.
-- (Safe update mode가 ON 되어있다면 오류로 인식한다.)
DELETE FROM 테이블 WHERE 레코드 조건;
다양한 명령어
- 출력 (SELECT)
1
SELECT 필드명 FROM 테이블;
- 조건문 (WHERE)
1
SELECT 필드명 FROM 테이블 WHERE 조건1 AND 조건2 AND 조건3 ...;
- 연산자 (+, >, <, AND, OR 등등..)
1
2
SELECT 필드명1, 필드명2, 필드명1+필드명2 FROM 테이블;
(결과는 숫자의 기준으로 나옴 1+'A'=1)
- 정렬 (ORDER BY)
1
2
오름차순 : SELECT * FROM 테이블 ORDER BY 필드명 ASC;
내림차순 : SELECT * FROM 테이블 ORDER BY 필드명 DESC;
- 제한 (LIMIT)
1
2
3
4
5
6
SELECT * FROM 테이블 LIMIT 반환갯수;
SELECT * FROM 테이블 LIMIT 시작위치, 반환갯수;
EX)
SELECT * FROM 테이블 LIMIT 5; -- 0 ~ 4 까지 출력
SELECT * FROM 테이블 LIMIT 2, 5; -- 3 ~ 7 까지 출력
- 필드명 변경(AS (생략가능))
1
SELECT 필드명1 (AS) "변경할이름" FROM 테이블;
- 구간데이터 출력(BETWEEN)
1
2
3
4
5
SELECT * FROM 테이블 WHERE 필드명 BETWEEN 500 AND 900;
#(해당 필드명의 값이 500과 900 사이인 레코드들을 선택)
SELECT * FROM 테이블 WHERE 필드명 >= 500 AND 필드명 <=900
# 다음과 동일
- 포함 여부 (IN)
1
2
SELECT * FROM 테이블명 WHERE 필드명 IN('후보1', '후보2', '후보3');
# 후보들중 나오는 값을 의미
- 문자열검색 (LIKE)
1
2
3
4
5
SELECT * FROM 테이블명 WHERE 필드명 LIKE 'NEW%';
# NEW로 시작하는 모든 문자를 검색 %는 다중문자를 의미
SELECT * FROM 테이블명 WHERE 필드명 LIKE 'K_R';
# K_R로 이루어진 모든 문자를 검색 _는 한 글자를 의미
- 그룹을 지어 데이터를 묶기(GROUP BY)
집계함수 : SUM, AVG, MIN, MAX, COUNT 등을 사용하기위해 묶음.
1
2
SELECT * FROM 테이블명 GROUP BY 필드명1
# 테이블에서 필드명1 을 기준으로 다른 데이터들을 묶는다.

- GROUP BY와 함께 쓰는 조건절, 집계함수에 대한 조건을 걸 수 있음(HAVING)
1
2
SELECT COUNT(필드2) AS '인구수' FROM 테이블명 GROUP BY 필드1 HAVING COUNT(필드2) > 200;
# 필드1 기준으로 데이터들을 묶어 필드2의 합계가 200이 이상인 레코드들만 선택
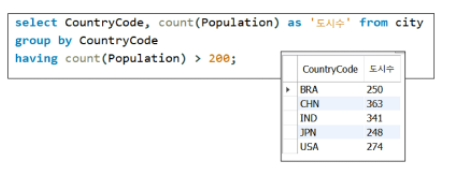
날짜 타입관련 함수 (생략)
- IS NULL / IS NOT NULL
1
2
3
4
5
SELECT * FROM 테이블 where 필드명 IS NULL;
# 필드명이 NULL인것들만 출력
SELECT * FROM 테이블 where 필드명 IS NOT NULL;
# 필드명이 NULL이 아닌것 들만 출력
- IFNULL (NULL을 다른 문자로 대체하기)
1
2
3
SELECT 필드1, IFNULL(필드2, '#') FROM 테이블명;
# 테이블에서필드2의 값이 NULL이면 '#'을 출력한다.
# ex) select num , name, IFNULL(age,'나이없음;') from honey;
- CONCAT (값을 합치는 함수)
1
2
3
SELECT CONCAT(필드1,"-",필드2,"-",필드3) FROM 테이블
# '필드1-필드2-필드3' 의 형태로 레코드들이 출력된다.
# ex) select concat('안녕','하','새우');
- CONVERT(타입을 변환하는 함수)
1
CONVERT(필드명, 변환TYPE)
두개이상의 테이블 관리(중요)
- MYSQL 합집합 (UNION)
1
2
3
select 필드명 from 테이블1 union select 필드명 테이블2
# union은 자동으로 중복을 제거해준다.
# union all 을 사용하면 중복이 제거 되지 않고 바로 나타내 준다.
- MYSQL 교집합 (JOIN)
1
2
테이블1 INNER JOIN 테이블2 ON 조건
select * from 테이블1, 테이블2 where 테이블1.name = 테이블2.name
1
2
3
4
5
6
7
8
9
10
11
12
JOIN (MYSQL - JOIN, INNER JOIN, CROSSJOIN 같은의미로 사용된다)
INNER JOIN - ON 조건절와 함께사용되며 ON의 조건을 만족하는 데이터만 가져온다.
(첫번째 테이블 INNER JOIN 두번째 테이블 ON 조건)
- - LEFT JOIN
-- 첫번째테이블을 기준으로 두번쨰 테이블을 조합하는 JOIN
-- 첫번째 테이블 이름 LEFT JOIN 두번째 테이블 이름 ON 조건
-- ON조건을 만족하지 않는 경우에는 첫번쨰 테이블 필드의 값은 그대로 가져온다
- - RIGHT JOIN
-- 두번째 테이블을 기준으로 첫번째 테이블을 조합
-- ON조건을 만족하지 않는 경우에는 두번쨰 테이블 필드의 값은 그대로 가져온다
-- 첫번째 테이블 이름 RIGHT JOIN 두번째 테이블 이름 ON 조건 - **MYSQL 차집합 (SUBQUERY)**
1
2
select id from 테이블1 where id not in(select id from 테이블2)
select 테이블1.id from 테이블1 LEFT JOIN 테이블2 ON 테이블1.id = 테이블2.id where 테이블2.id is null
1
2
3
- 서브 쿼리
-- 쿼리문안에 쿼리문이 있는것을 서브쿼리라고 부른다
-- 조건문들을 만들때, 값을 직접지정하지 못하고 쿼리문을 통해 구해와야 할경우 서브쿼리를 통해 값을 가져온다.
대표적인 데이터 타입
- 숫자형
- Int : 약 -21억 ~ 21억 사이 정수
- float (3,1) : 정수부 3자리 / 소수점 1자리 허용
- 문자형
-
char(35) : 35 byte 만큼 char 사용
→ 빠른 성능이 필요한, 자주 읽는 필드
-
varchar(10) : 가변 데이터 타입, 빈 공간을 채우지 않음. ‘bts’를 넣으면 3byte만 사용함. (공간은 아낄 수 있지만, 데이터 파편화로 성능 저하)
→ 길이 변화가 큰 문자에 사용
-
text : 64kb 미만의 긴 문자열
-
- 날짜형
- date : 날짜 타입 기본 format은 YYYY-MM-DD
- datetime : 날짜 + 시간을 나타냄. YYYY-MM-DD HH:MM:SS
- JSON type
-
JSON Data를 저장할 수 있는 Type

-
DB 구하기 및 실습
mysql 사이트에서 document > More클릭을 통해서 연습에 필요한 DB를 다운받을 수있다.
employee 데이터를 이용하여 sql 명령어를 사용해보자.
https://github.com/datacharmer/test_db
employees 테이블 first_name 이름 last_name 성 emp_no - 사원번호 birth_date - 생일 gender 성별 hire_date - 고용일
salaries 테이블 emp_no - 사원번호 salary - 급여 from_date 급여 수령 시작일 to_date 급여 수령 종료일
titles 테이블 emp_no - 사원번호 title: 직급 from_date 시작일 to_date 종료일
departments 테이블 dept_no - 부서 번호 dept_name - 부서 이름
dept_emp 테이블 emp_no - 사원번호 dept_no - 부서번호 from_date - 시작일 to_date - 종료일
dept_manager 테이블 emp_no - 사원번호 dept_no - 부서번호 from_date - 시작일 to_date - 종료일
실습해보기
사원의 수를 성별로 가져온다.
select gender ,count(_) from employees group by gender;__급여수령 시작일별(from_date) 별 급여의 총합(salary)을 구하기_
_select from_date ,sum(salary) from salaries group by from_date;__5만명이상 근무하고 있는 부서의 부서번호와 부서 소속 사원수 가져오기_
_select dept_no, count(*) from dept_emp group by dept_no having count(*) > 50000_테이블 두개 이상 합치기
각 사원들의 사원번호, first_name, 근무 부서 이름 가져오기 (employees에 사원번호, first_name 근무 부서이름은 departments 에 있다**) - JOIN**
```sql select a.emp_no, first_name, dept_name from employees a, dept_emp b, departments c where a.emp_no = b.emp_no and b.dept_no = c.dept_no order by emp_no desc; ```현재 받는 급여의 평균보다 많이 받는 사원들의 사원번호, 급여액 가져오기 - **SUBQUERY**
```sql -- step 1 일반 급여 평균 select avg(salary) from salaries; -- step 2 급여가 평균보다 많이 받이 받았을 때의 경우 모두 출력 select emp_no, salary from salaries where salary > (select avg(salary) from salaries); -- 응용 select emp_no, salary, to_date from salaries where salary > ( -- ()안의 내용은 현재 받는 급여의 평균을 가져오는 서브쿼리 select avg(salary) from salaries where to_date = '9999-01-01' -- and to_date = 현재 근무중인것을 구분하기 위해서 가져온다 ) and to_date = '9999-01-01'; ```1960년 이후에 태어난 사원들의 사원번호, 근무 부서번호를 가져오기 - **둘다 사용**
```sql -- join ver select b.emp_no, dept_no from dept_emp a, employees b where a.emp_no=b.emp_no and birth_date >= 1960-01-01; - subQuery ver select emp_no, dept_no from dept_emp where emp_no in(select emp_no from employees where birth_date >= 1960-01-01); ```SQL의 실력향상
sql의 실력을 높이기 위해서 프로그래머스 사이트에서 연습할 수있다.
https://programmers.co.kr/learn/challenges?tab=sql_practice_kit